Research
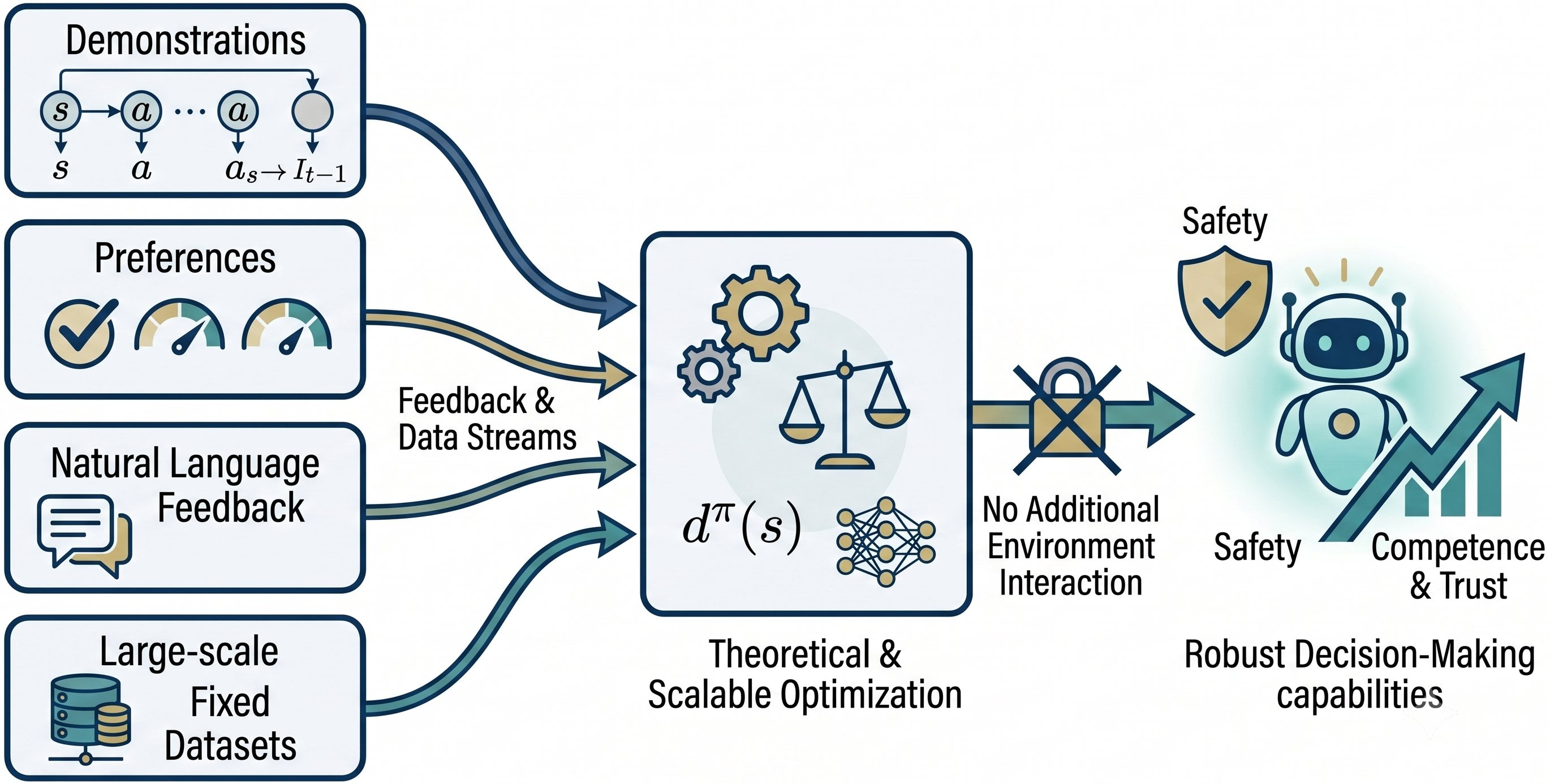
I develop learning algorithms that enable AI agents to acquire robust decision-making capabilities from fixed data and rich feedback. My research spans reinforcement learning, imitation learning, foundation models, and AI agents, with a focus on building competent, trustworthy, and generalizable policies without additional environment interaction. By combining theoretical foundations with scalable algorithms, I aim to create autonomous systems that can learn safely and efficiently from demonstrations, preferences, natural language feedback, and large-scale datasets. Below are my publications, patents, and selected projects.
Reinforcement Learning
Imitation Learning
Behavior Foundation Models
Agentic AI
Large Language Models
Post-training
Publications 10
NEW RLxF Workshop · ICML 2026
Reinforcement Learning from Rich Feedback with Distributional DAgger
Rishabh Agrawal, Jacob Fein-Ashley, Paria Rashidinejad
Abstract
Reasoning models have advanced quickly, but the dominant RL-from-verifiable-rewards (RLVR) recipe stays narrow: sample many responses and reward each with a single correctness bit. Many settings, though, provide far richer feedback — execution traces, tool outputs, expert corrections, and self-evaluations. We use such feedback through DistIL, a distributional variant of the classic DAgger algorithm in which the learner has local access to an expert distribution over the states its current policy visits. This yields a simple forward cross-entropy objective that admits a black-box expert and whose sequence-level gradient propagates future expert–student disagreement back to earlier decisions. We show that prior self-distillation objectives based on reverse-KL or Jensen–Shannon do not guarantee monotonic policy improvement, whereas forward cross-entropy does — and additionally enjoys regret guarantees and optimizes a lower bound on teacher-weighted likelihood of success, improving Pass@N. Empirically, DistIL improves over RLVR and self-distillation baselines across scientific reasoning, coding, and hard mathematics.
NEW arXiv · 2026
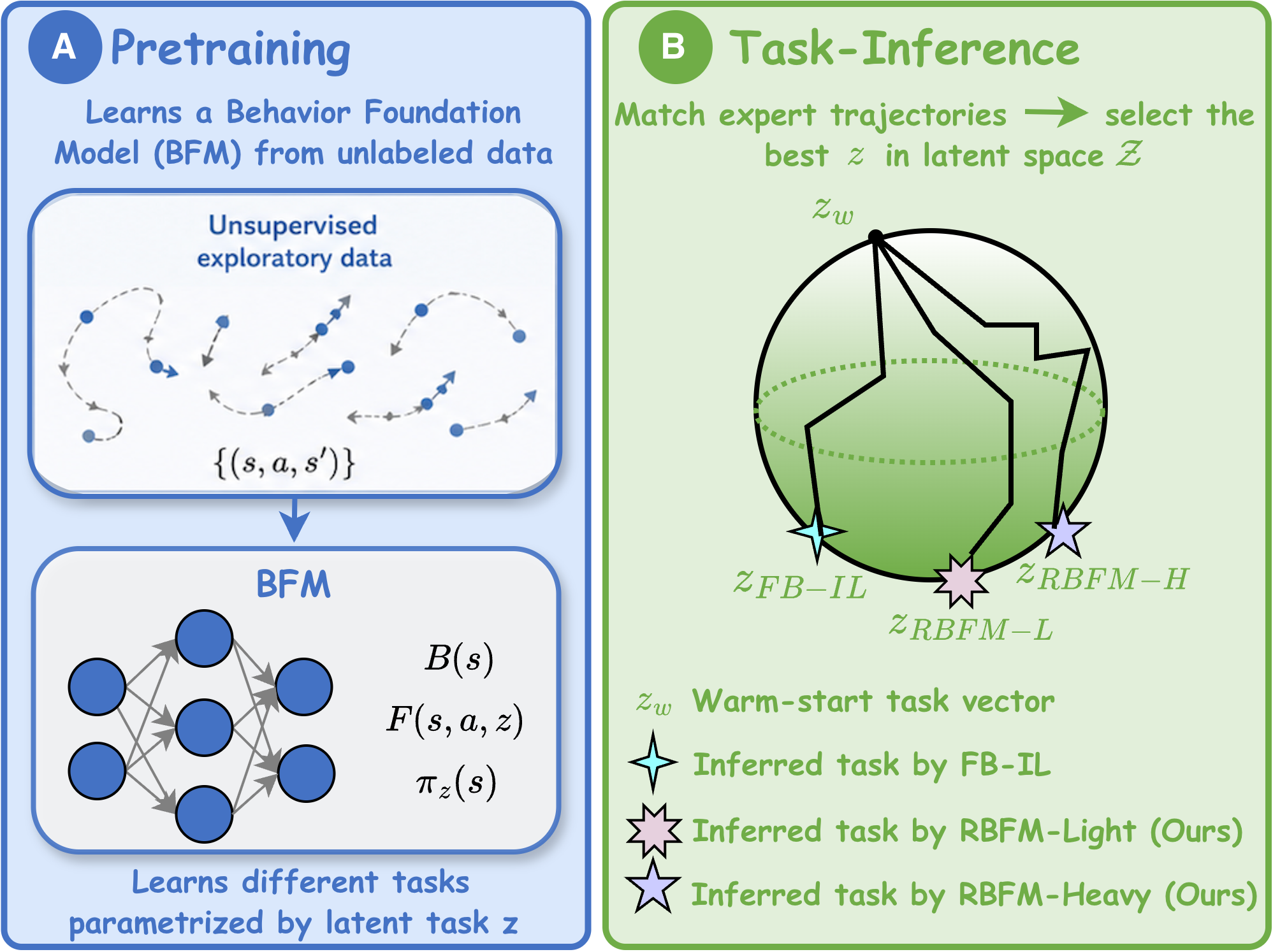
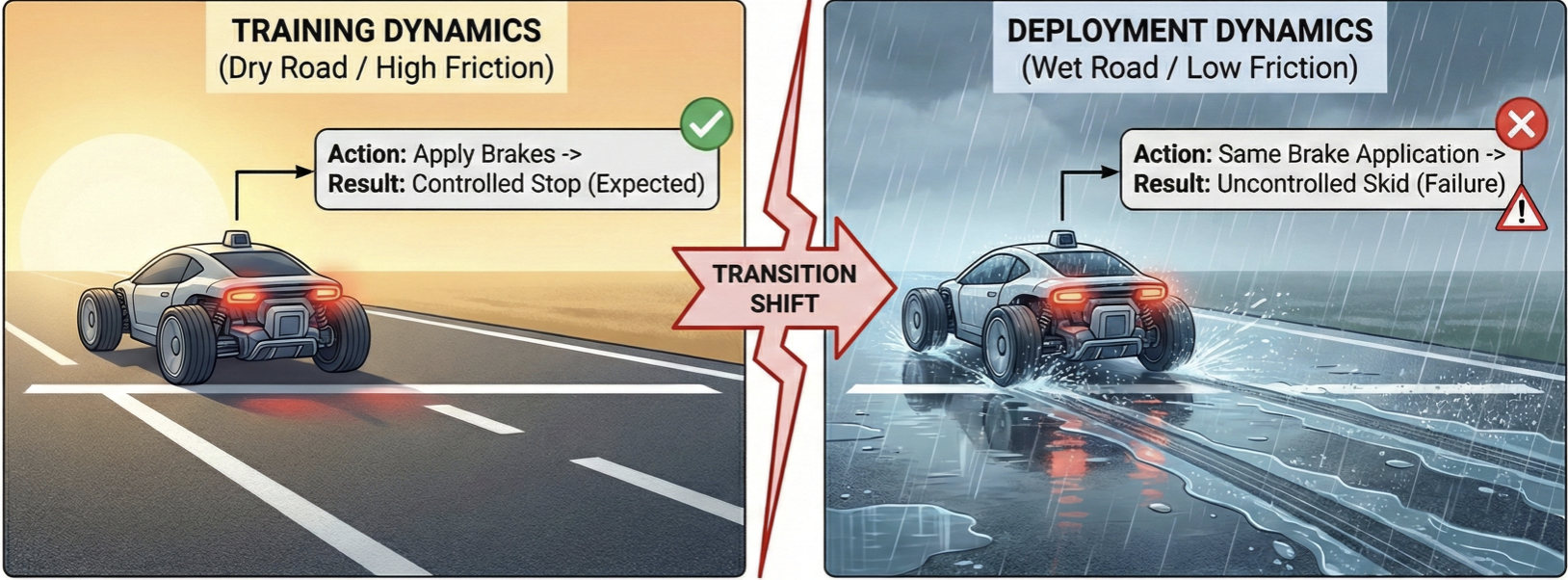
When Dynamics Shift, Robust Task Inference Wins: Offline Imitation Learning with Behavior Foundation Models Revisited
Rishabh Agrawal, Rahul Jain, Ashutosh Nayyar
Abstract
Behavior Foundation Models (BFMs) enable scalable imitation learning by pretraining task-agnostic representations that adapt rapidly to new tasks — but existing BFMs assume fixed dynamics, limiting robustness under real-world shifts such as changes in friction, actuation, or sensor noise. We formulate BFM task inference as a robust minimax optimization over an uncertainty set of dynamics, enabling adaptation to worst-case perturbations without touching pretraining. To our knowledge this is the first BFM framework robust to dynamics shifts while using only offline data from a single nominal environment. Two variants, RBFM-Light and RBFM-Heavy, trade computation against robustness while preserving fast task inference, and both significantly outperform standard BFM and robust offline IL baselines under dynamics shifts.
ORAL NeurIPS 2025 E-SARS · L4DC 2026
Balance Equation-based Distributionally Robust Offline Imitation Learning
Rishabh Agrawal, Yusuf Alvi, Rahul Jain, Ashutosh Nayyar
Abstract
Standard imitation learning implicitly assumes environment dynamics remain fixed between training and deployment — an assumption that rarely holds, since modeling inaccuracies, parameter variation, and adversarial perturbations all shift transition dynamics and degrade performance. We learn robust policies from expert demonstrations collected under nominal dynamics alone, formulating the problem as a distributionally robust optimization over an uncertainty set of transition models. Crucially, we show this worst-case objective can be reformulated entirely in terms of the nominal data distribution, enabling tractable offline learning. On continuous-control benchmarks, the approach achieves superior robustness and generalization over state-of-the-art offline IL baselines, especially under perturbed or shifted environments.
AAAI 2026 · Doctoral Consortium
Towards Offline Imitation Learning: Strictly Batch Settings, Generalization, and Variability in Expertise
Rishabh Agrawal
Abstract
My doctoral research develops a unified framework for offline imitation learning that tackles three challenges: sample efficiency in strictly batch settings, robustness and generalization under dynamics shifts, and learning from demonstrations of varying quality. At its core is a paradigm for strictly offline IL based on enforcing the Markov Balance Equation, realized through conditional density estimation in the CKIL and MBIL algorithms. Building on this, I developed the first distributionally robust offline IL framework under a stationarity constraint, and now extend it through Robust Behavior Foundation Models that generalize across dynamics shifts. Finally, I propose a variational approach for learning from crowdsourced demonstrations by inferring demonstrator expertise — together broadening the applicability of IL to robotics, healthcare, and autonomous systems.
AAAI 2025
Markov Balance Satisfaction Improves Performance in Strictly Batch Offline Imitation Learning
Rishabh Agrawal, Nathan Dahlin, Rahul Jain, Ashutosh Nayyar
Abstract
We address imitation where the learner relies solely on observed behavior, with no environment interaction, no supplementary datasets beyond the expert's, and no knowledge of transition dynamics — a more constrained and realistic setting than most SOTA IL methods assume. Our method uses the Markov balance equation and introduces a conditional density estimation framework, employing conditional normalizing flows for transition dynamics estimation to satisfy a balance equation for the environment. Across Classic Control and MuJoCo, it consistently outperforms many state-of-the-art IL algorithms.
L4DC 2025
Conditional Kernel Imitation Learning for Continuous State Environments
Rishabh Agrawal, Nathan Dahlin, Rahul Jain, Ashutosh Nayyar
Abstract
Classical IL methods such as behavioral cloning and inverse RL are highly sensitive to estimation errors, an acute problem in continuous state spaces, while distribution-matching approaches often require additional online interaction. We consider imitation in continuous state environments based solely on observed behavior — without transition dynamics, reward structure, or any further interaction. Our approach builds on the Markov balance equation with a conditional kernel density estimation framework, estimating dynamics via conditional kernel density estimators that satisfy the environment's probabilistic balance equations. We establish asymptotic consistency and show consistently superior empirical performance over many state-of-the-art IL algorithms.
OPT for ML · NeurIPS 2024
Policy Optimization for Strictly Batch Imitation Learning
Rishabh Agrawal, Nathan Dahlin, Rahul Jain, Ashutosh Nayyar
Abstract
We address imitation based solely on observed behavior — without transition dynamics, reward structure, or any additional environment interaction. The approach leverages conditional kernel density estimation and performs policy optimization to satisfy the Markov balance equation associated with the environment, working effectively in both discrete and continuous state settings under strictly offline optimization. We establish basic asymptotic consistency and show consistently superior empirical performance over many state-of-the-art IL algorithms.
IEEE Globecom 2020
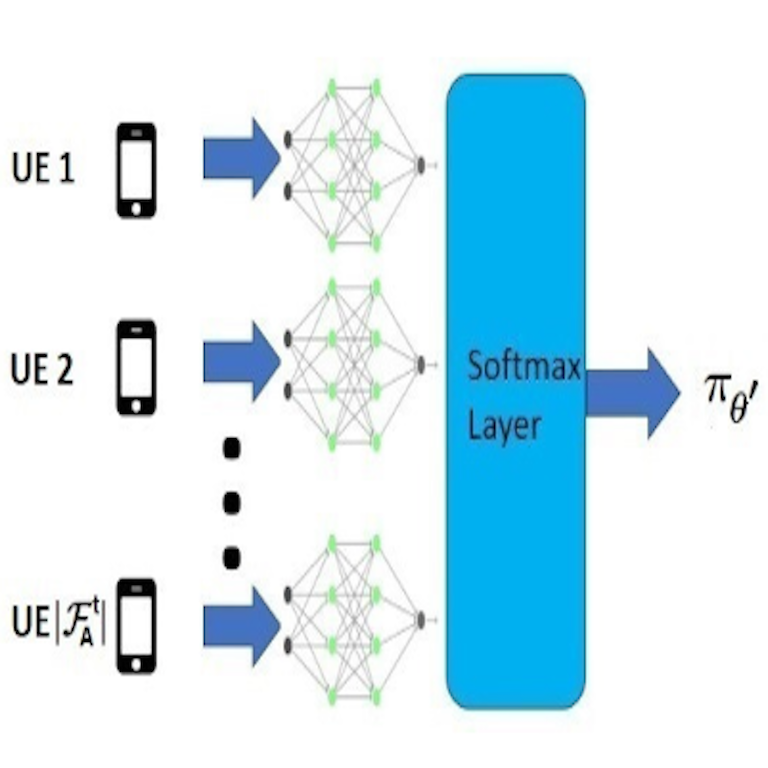
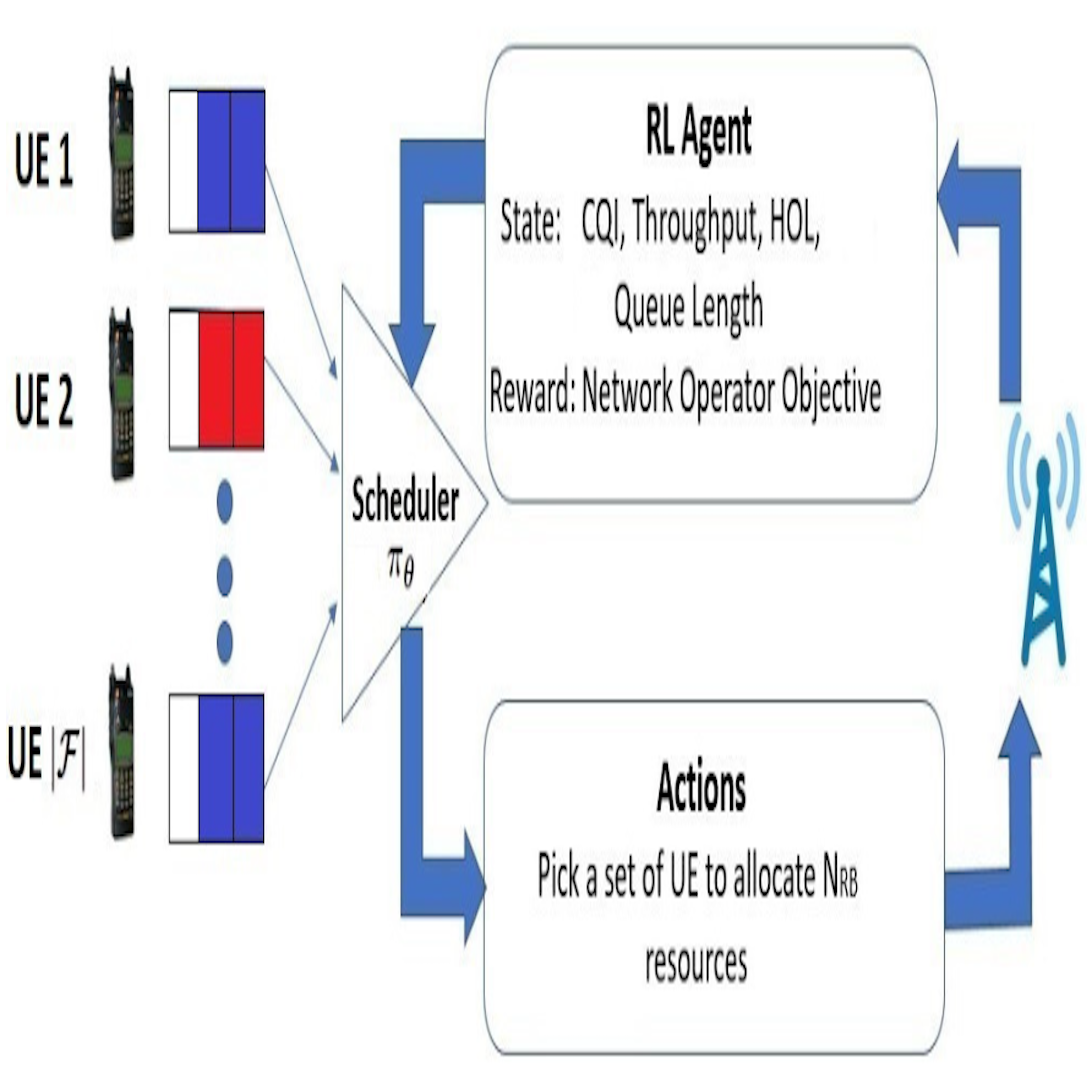
A Reinforcement Learning Framework for QoS-Driven Radio Resource Scheduler
Jitender Singh Shekhawat, Rishabh Agrawal, K. Gautam Shenoy, Rajath Shashidhara
Abstract
In cellular systems the MAC scheduler allocates radio resources to meet each flow's quality-of-service requirements while maximizing throughput and fairness — a delicate balance traditionally struck with hand-crafted, carefully tuned metrics that 5G's diverse QoS needs further complicate. We propose a reinforcement learning scheduler that learns an allocation policy to jointly optimize multiple objectives, letting operators express priorities per QoS class. A flexible neural architecture adapts to varying numbers of flows, simplifying training and making it viable for constrained systems. In simulation it outperforms conventional heuristics such as M-LWDF, EXP-RULE, and LOG-RULE and stays robust to changes in radio environment and traffic.
LOD 2019
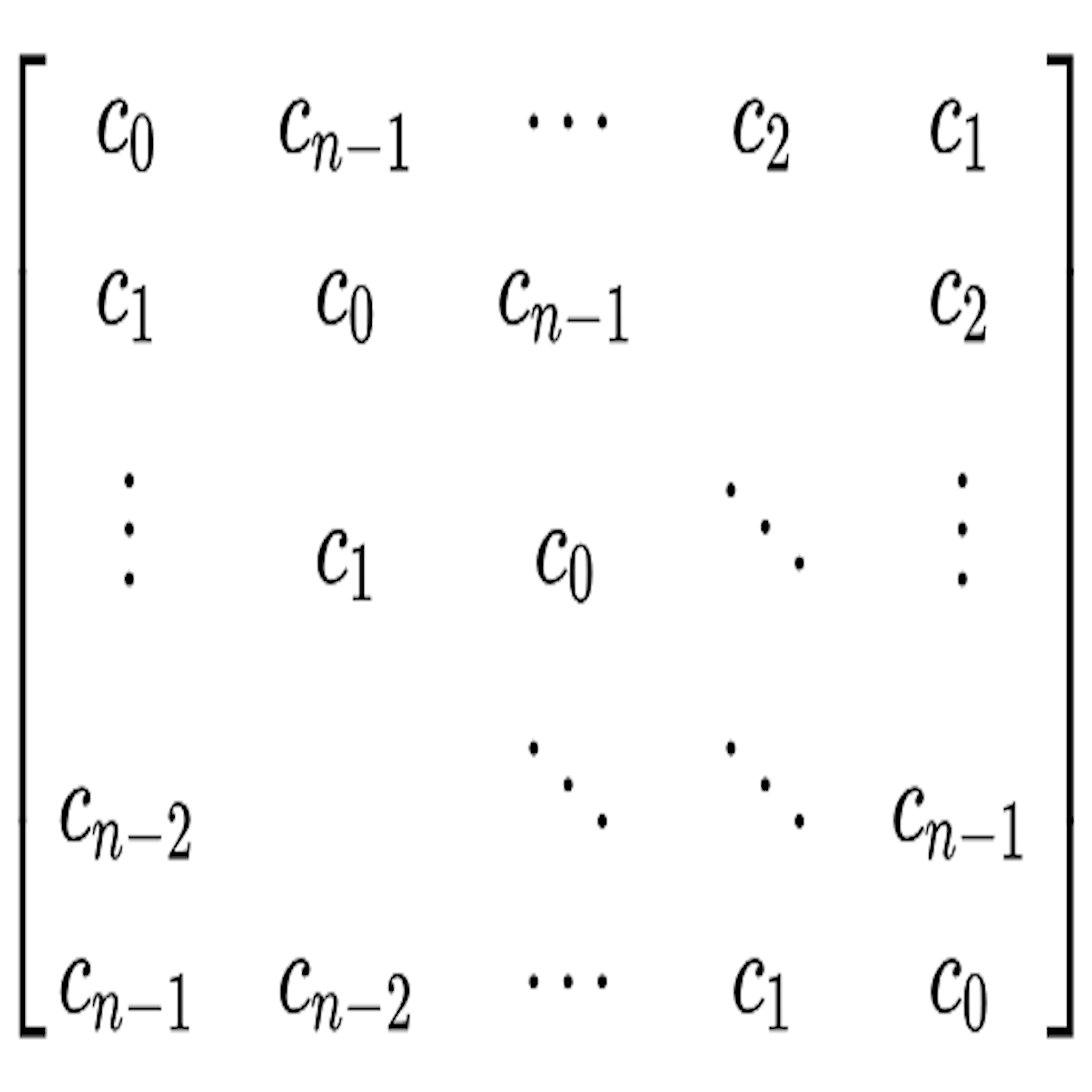
CoPASample: A Heuristics Based Covariance Preserving Data Augmentation
Rishabh Agrawal, Paridhi Kothari
Abstract
Effective data augmentation generates samples that improve a model's accuracy and robustness. We propose CoPASample, an algorithm that generates samples reflecting the first- and second-order statistics of the dataset, augmenting it while preserving total covariance. To avoid the exponential cost of generating augmentation points, we formulate an optimization problem motivated by the ν-SVR approach to iteratively compute a heuristic-based optimal set of points in polynomial time. Experiments across several datasets, with comparisons to other augmentation methods, validate the approach.
FUZZ-IEEE 2018
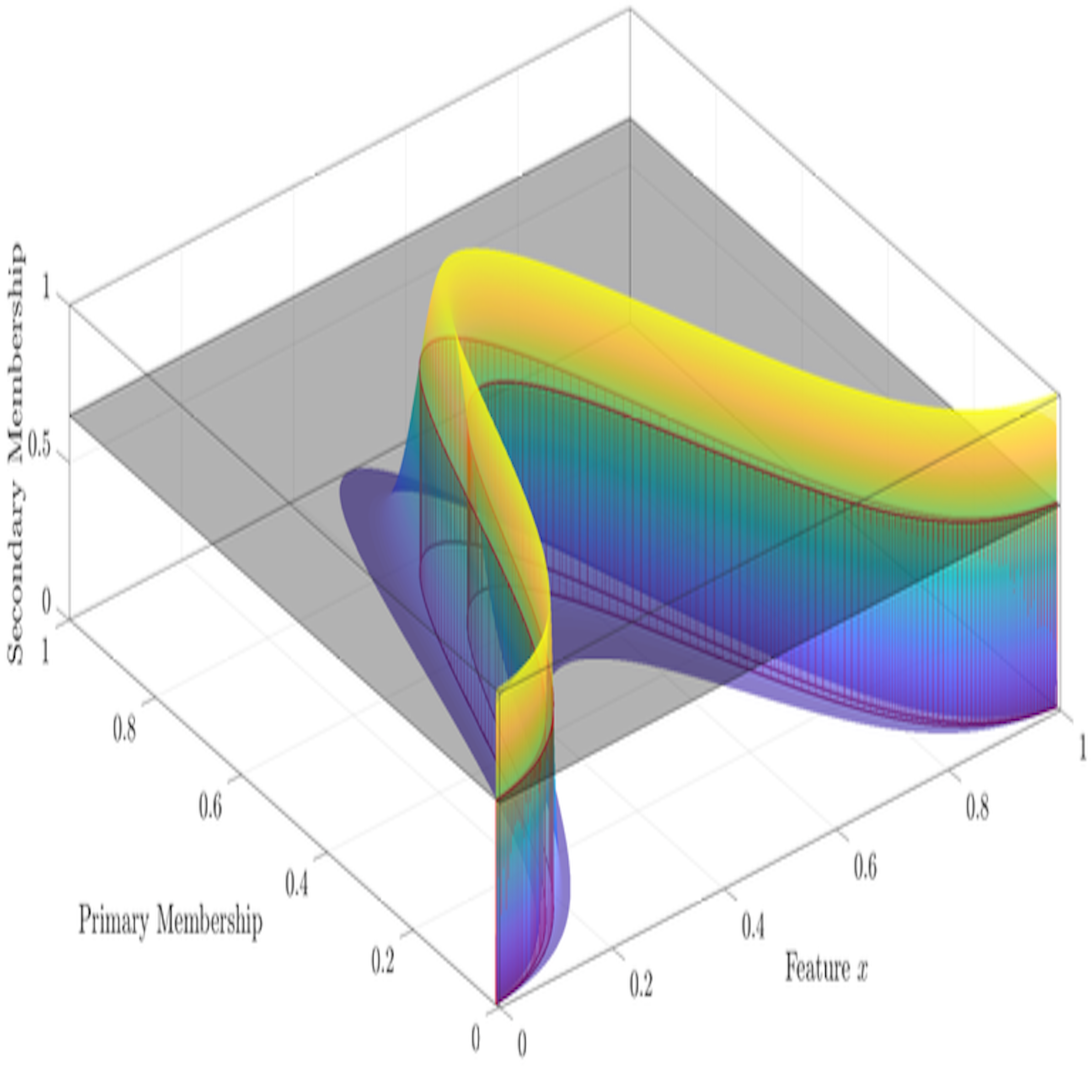
Determining the Optimal Fuzzifier Range for Alpha-Planes of General Type-2 Fuzzy Sets
Shreyas Kulkarni, Rishabh Agrawal, Frank Chung-Hoon Rhee
Abstract
The fuzzifier parameter strongly shapes the final cluster partitions in fuzzy c-means and its interval and general type-2 variants, yet is usually chosen by experience. We adaptively compute suitable fuzzifier ranges for each α-plane of a general type-2 fuzzy set for a given dataset, deriving the footprint of uncertainty per α-plane via histogram-based membership generation and iterating to converged fuzzifier values. Experiments on several datasets validate the method's effectiveness.
Patents 1
US Patent · 2022
Method and System for Radio-Resource Scheduling in Telecommunication Network
Jitender Singh Shekhawat, Rishabh Agrawal, Anshuman Nigam, Konchady Gautam Shenoy, Yash Jain
Abstract
A method for radio-resource scheduling in a telecommunication network that selects an objective from a set of objectives, prioritizes flows accordingly, and feeds state parameters of active bearers into a reinforcement learning network configured with a reward aligned to the selected objective, which then returns a per-bearer radio resource allocation for the current transmission time interval.
Projects 5
Multimodal · Diffusion
Restoring Multimodal Missing Modalities with Diffusion Models
Diffusion-based modality restoration conditioned on available modalities for personality-trait prediction.
Abstract
Real-world multimodal datasets are often incomplete, degrading downstream prediction. We condition a trained diffusion model on the available modalities to reconstruct the missing one, extracting emotion-rich features from text, video, and audio and exploring early, late, and transformer-based fusion to integrate reconstructed modalities for personality-trait inference. We evaluate on the ChaLearn First Impressions V2 dataset.
RLHF · LLM
RLHF-based Optimization of Recommendations using a Large Language Model
A recommendation system that aligns an LLM's reward model with user preferences via RLHF and DPO.
Abstract
We study optimizing LLM-based recommenders with two methodologies — Reinforcement Learning from Human Feedback and Direct Preference Optimization — developing separate pipelines to fine-tune LLMs for inferred user preferences. On MovieLens, supervised fine-tuning and preference tuning both improve recommendation quality, highlighting the potential and limits of LLM-based systems for recommendation.
Offline RL · VQ-VAE
Action-Quantized Offline Reinforcement Learning
State-conditioned action quantization with VQ-VAE, jointly trained with offline RL for ~20% gains.
Abstract
Continuous action settings often force approximations that hurt offline RL, while discrete settings allow more precise constraints and regularizers. Using a VQ-VAE, we learn state-conditioned action quantization (SAQ) to avoid the exponential complexity of naive discretization, strengthening methods such as IQL and CQL. Jointly training the VQ-VAE with the offline RL objective yields further gains — roughly 20% improvements on locomotion, adroit, and kitchen tasks.
Gradient Boosting · Ensemble
Earthquake Damage Prediction
Feature engineering and ensembling (LightGBM, CatBoost, XGBoost); F1 = 0.7541, 2nd of 50 teams.
Abstract
Using building location and construction data from the 2015 Gorkha earthquake in Nepal, we predict per-building damage levels with feature engineering, gradient-boosting algorithms, and ensemble models, achieving an F1 score of 0.7541 on the test set.
Optimization · Augmentation
Application of r-Cyclic Matrices in Data Augmentation
A covariance-preserving augmentation scheme with a polynomial-time heuristic, motivated by ν-SVR.
Abstract
To counter data insufficiency while preserving covariance after augmentation, we design an algorithm that turns the otherwise exponential computation into polynomial time via a heuristic, formulating an optimization problem motivated by ν-SVR. Experiments on several UCI datasets across multiple classifiers demonstrate the effectiveness of the approach.