I am a Ph.D. candidate in Electrical & Computer Engineering at the University of Southern California, where I completed master's degrees in both Computer Science and Electrical Engineering in May 2025. My research, advised by Prof. Rahul Jain and Prof. Ashutosh Nayyar, centers on reinforcement learning (RL), with a particular focus on offline and robust imitation learning, behavior foundation models, and post-training LLMs. I also collaborate closely with Prof. Paria Rashidinejad on RL for LLMs research.
The dominant RL-from-verifiable-rewards recipe rewards each response with a single correctness bit, yet many settings provide far richer feedback — execution traces, tool outputs, expert corrections, self-evaluations. We study how to use such feedback through DistIL, a distributional variant of DAgger that optimizes a forward cross-entropy objective. Unlike reverse-KL or Jensen–Shannon self-distillation, DistIL guarantees monotonic policy improvement and sublinear regret, performs future-aware credit assignment, and improves Pass@N across scientific reasoning, coding, and hard mathematics.
NEW arXiv · 2026
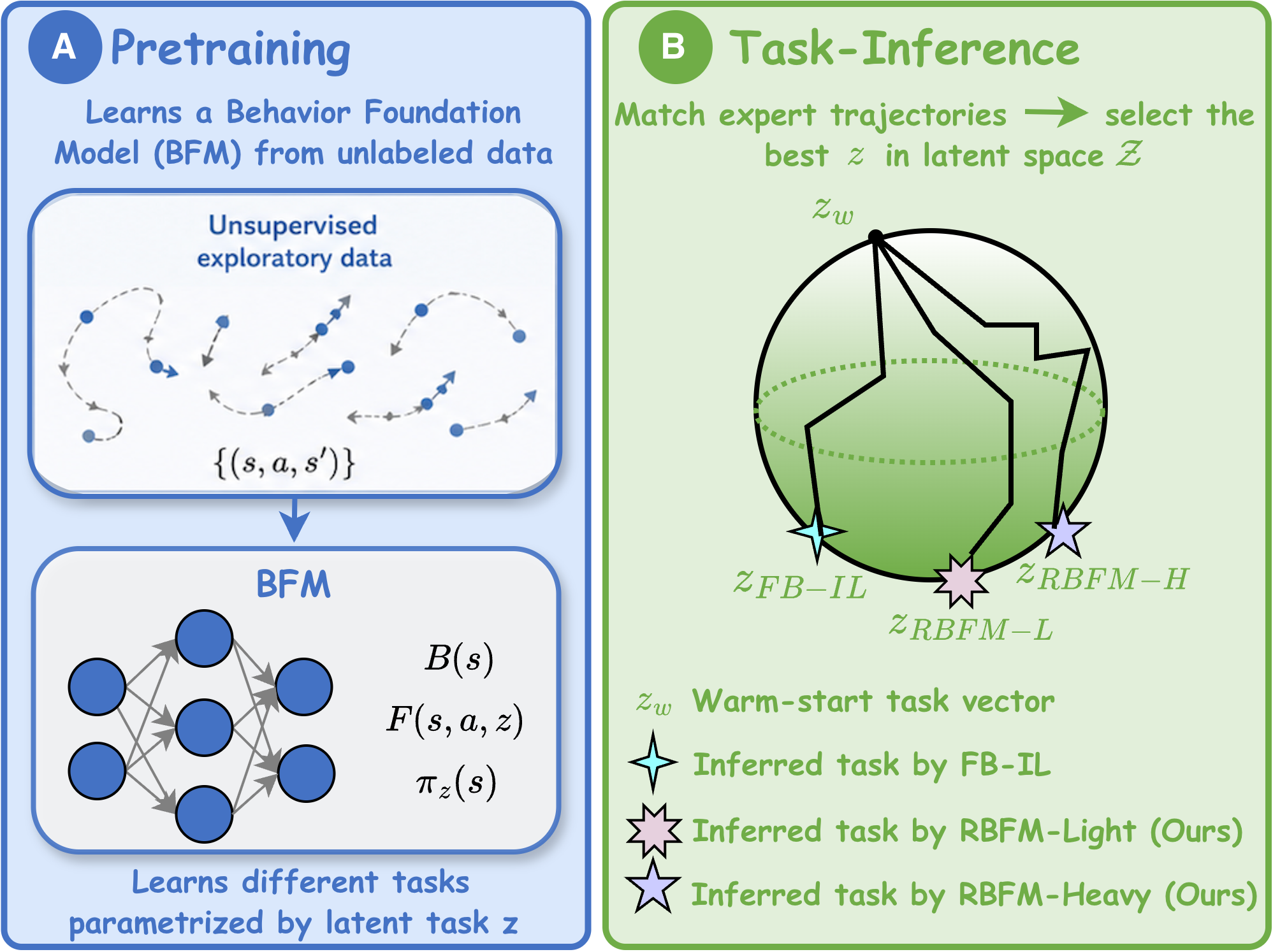
When Dynamics Shift, Robust Task Inference Wins: Offline Imitation Learning with Behavior Foundation Models Revisited
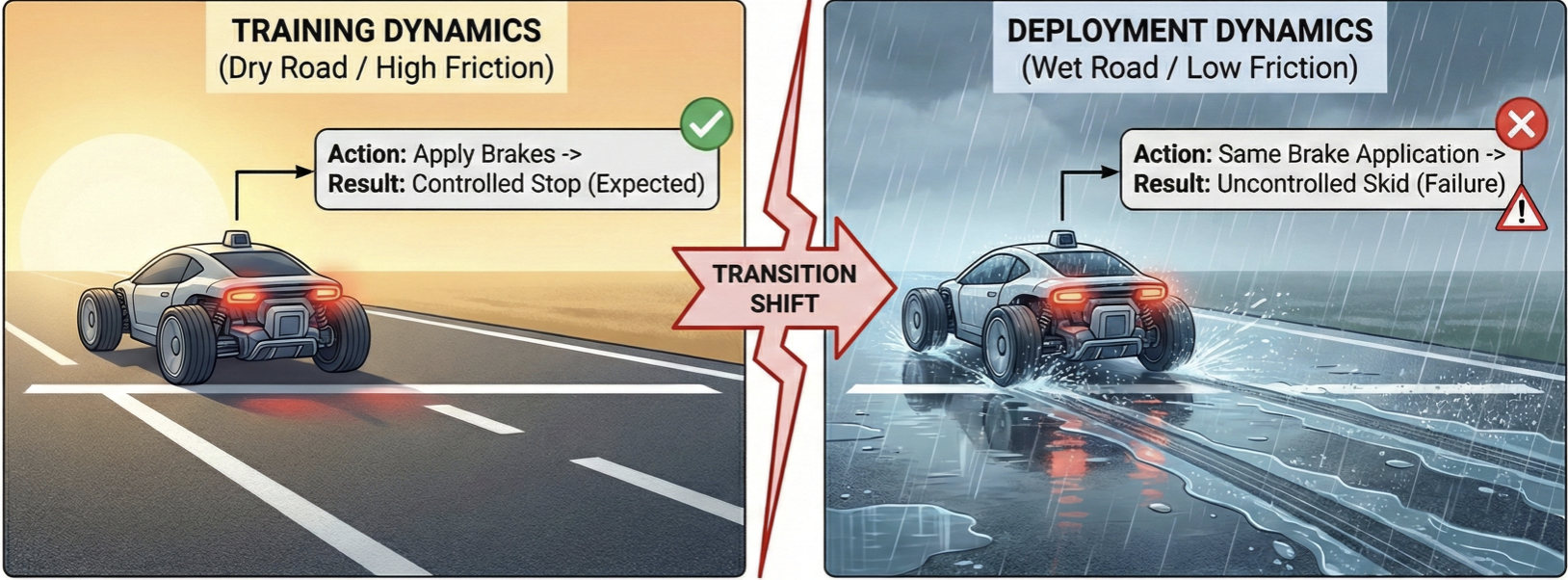
Behavior Foundation Models (BFMs) enable scalable imitation learning but assume fixed dynamics, leaving them brittle to real-world shifts in friction, actuation, or sensor noise. We recast BFM task inference as a robust minimax problem and introduce RBFM-Light and RBFM-Heavy — two variants that add robustness only at inference, with no change to pretraining and using offline data from a single nominal environment. Both substantially outperform standard BFM and robust offline IL baselines under dynamics shifts.
Standard imitation learning implicitly assumes the environment stays fixed between training and deployment — an assumption that rarely holds. We learn robust policies from expert demonstrations alone by solving a distributionally robust optimization over an uncertainty set of transition models, and show the worst-case objective can be rewritten entirely in terms of the nominal data distribution, enabling tractable offline learning with stronger robustness under shifted dynamics.
We study imitation in a strictly offline setting — no environment interaction, no auxiliary data, no transition model. Our method uses the Markov balance equation with a conditional density estimation framework, employing conditional normalizing flows for dynamics, and consistently outperforms many state-of-the-art IL algorithms across Classic Control and MuJoCo.